
Reti Neurali per l’analisi delle serie storiche. Un’applicazione a dati di qualità dell’aria: il caso Moggio.
In questo articolo vengono illustrate le potenzialità delle reti neurali per analizzare dati di qualità dell’aria misurati da alcune stazioni di monitoraggio presenti in regione Lombardia.
Reti Neurali per l’analisi delle serie storiche. Un’applicazione a dati di qualità dell’aria: il caso Moggio.
In questo articolo vengono illustrate le potenzialità delle reti neurali per analizzare dati di qualità dell’aria misurati da alcune stazioni di monitoraggio presenti in regione Lombardia.
Le reti neurali, proposte per la prima volta nel 1943, sono diventate nel corso degli ultimi anni strumenti di analisi dei dati largamente utilizzati, specialmente in applicazioni caratterizzate da un’elevata complessità. Il loro crescente utilizzo è principalmente legato ad una maggiore quantità di dati liberamente disponibili e alla riduzione dei costi per le risorse computazionali.
Se pensiamo allo studio della qualità dell’aria, possiamo immaginare l’atmosfera come una miscela gassosa composta da diverse sostanze. Le concentrazioni di queste sostanze dipendono da molti fattori come, ad esempio, le condizioni metereologiche e le caratteristiche socio-economiche della regione oggetto di studio, ma anche dalle reazioni chimiche che avvengono tra le stesse sostanze presenti in atmosfera.
Una situazione quindi decisamente complessa, che coinvolge svariati fattori e che in ultima battuta hanno un effetto sulla qualità dell’aria, espressa in termini di concentrazioni di inquinanti (per una panoramica sulla qualità dell’aria in Lombardia nel 2021 si veda il report ARPA 2021). In questo contesto le reti neurali possono essere un utile strumento di analisi in grado di cogliere la complessità che caratterizza il fenomeno analizzato e le variabili coinvolte.
Per studiare la potenziale relazione tra concentrazioni di ammoniaca e di particolato atmosferico (PM10 e PM2.5) in Lombardia, sono state testate diverse tipologie di reti neurali. In particolare, sono state utilizzate le architetture di reti neurali dette “Long-Short Term Memory” (LSTM) indicate per modellare serie storiche in cui i valori ad un certo istante temporale dipendono dai valori precedenti (si parla di memoria del modello).
I modelli implementati permettono anche di gestire dati mancanti nel dataset, una situazione frequente che si verifica quando le centraline di misura sono disattivate causando la mancata raccolta dei dati (ad esempio per situazioni di test dei sensori, di taratura degli strumenti, di collaudo, ecc.).
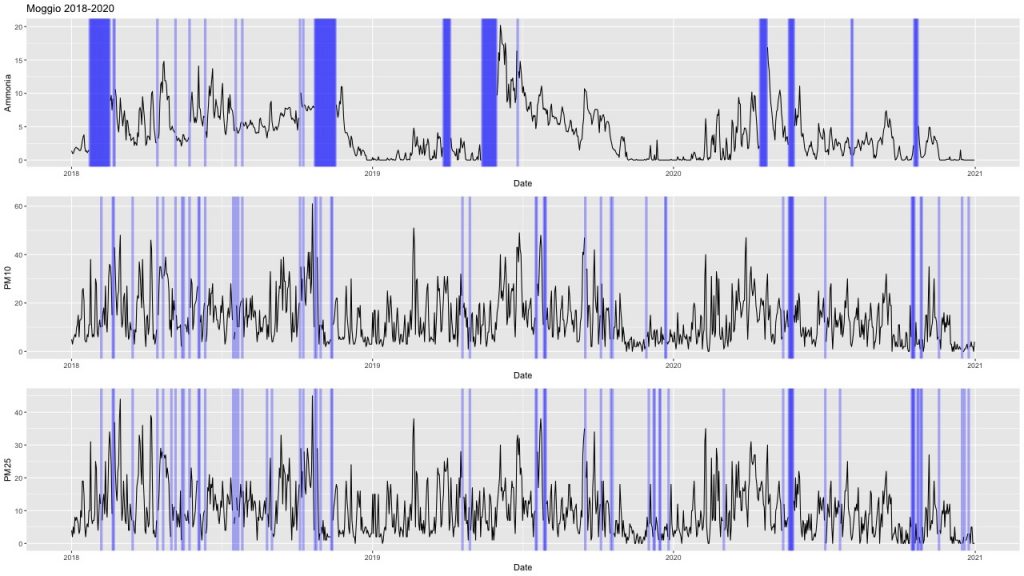
I grafici sottostanti riportano le serie storiche delle concentrazioni giornaliere di ammoniaca, PM10 e PM2.5 misurate nella stazione di Moggio (LC) negli anni 2018-2020. Come si può notare, i dati mancanti, evidenziati in blu nei grafici, sono parecchio frequenti e possono riguardare anche periodi prolungati nel tempo.
Caso studio e dati utilizzati
Usando i dati giornalieri disponibili per la centralina di Moggio dal 2014 al 2020, si intende stimare un modello di tipo LSTM per studiare la relazione tra le concentrazioni di PM10 (variabile target) e le concentrazioni di ammoniaca. Come regressori vengono inclusi nel modello anche variabili meteorologiche (velocità e direzione del vento, temperatura e precipitazioni) i cui dati provengono da tutte le centraline meteo dislocate in Lombardia.
Il caso studio è di particolare importanza in quanto riferito ad una stazione in contesto rurale, caratterizzato generalmente da elevate concentrazioni di ammoniaca dovute all’attività agricola-zootecnica.
Nel dettaglio, i dati dal 2014 al 2019 sono stati utilizzati per addestrare la rete neurale mentre l’anno 2020 è stato utilizzato per confrontare le previsioni date dal modello con i rispettivi dati reali. La memoria del modello è definita dai dati disponibili (sia della variabile target che dei regressori) dei cinque giorni precedenti consecutivi, necessari per calcolare la previsione del sesto giorno.
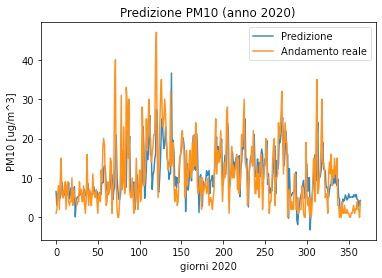
Il risultato di questa procedura, nota come predizione ad un giorno, è mostrata nel grafico seguente, dove sono confrontati i dati osservati (in arancione) e i dati predetti dal modello per il 2020 (in blu). Osserviamo un notevole grado di accuratezza in fase di predizione; ciò ci porta a concludere che le concentrazioni di ammoniaca e i fattori climatici (considerando i dati dei cinque giorni precedenti) sono in grado di spiegare le concentrazioni di PM10.
Come detto in precedenza, il modello viene addestrato usando i dati dal 2014 al 2019 mentre la previsione viene fatta per l’anno 2020, un anno noto per essere caratterizzato da periodi di lockdown adottati per arginare la diffusione del virus Covid-19.
E’ noto che durante i periodi di lockdown, soprattutto quello della primavera del 2020, le emissioni di inquinanti dal settore industriale e da fonti di traffico si sono ridotte, mentre le attività agricole non hanno subito un’interruzione dell’attività. In particolare, in contesti rurali non è stata misurata una diminuzione delle concentrazioni ammoniacali o di particolato (link). Pur essendo stato addestrato utilizzando dati riferiti ad anni senza lockdown, il modello offre previsioni valide. Questo può dare un importante suggerimento circa il ruolo dell’ammoniaca sulle concentrazioni di PM10 in un contesto rurale (per un maggiore dettaglio sulle emissioni agricole si veda La complessità dell’allevamento bovino da latte, un ciclo di due seminari organizzati da Agrimonia dal titolo: “Le caratteristiche della struttura dell’allevamento bovino in Italia e in Europea, con particolare riferimento alle emissioni azotate”).
Conclusioni
Il caso descritto in questo articolo è un ottimo esempio di quanto sia complesso lo studio della qualità dell’aria e di come l’utilizzo di reti neurali porti a prestazioni molto buone in termini di errore sulle previsioni. Ciò nonostante, le reti neurali utilizzate non sono in grado di sintetizzare l’informazione geografica portata dalle stazioni adiacenti. Infatti è ragionevole pensare che i dati siano caratterizzati da una correlazione spaziale e che localizzazioni spaziali “vicine” abbiano misure simili (in condizioni stazionarie) e che le concentrazioni di inquinanti si spostino da una località all’altra anche a seguito dell’azione del vento. Quindi non soltanto le condizioni “locali” di una particolare stazione ma anche le condizioni delle stazioni adiacenti influiscono sulle concentrazioni di inquinanti. Al fine di cogliere questa struttura di dipendenza nello spazio, è possibile utilizzare modelli statistici (di tipo parametrico) spazio-temporali (si vedano ad esempio Fioravanti et al. 2021, Finazzi e Fassò 2015, Fassò et al. 2021) o combinare questi ultimi con le reti neurali. In questo caso si parlerà quindi di modelli ibridi (unione di reti neurali con modelli statistici). Il progetto Agrimonia considererà tutti i diversi approcci: sia metodi di Machine Learning (come le reti neurali), sia metodi statistici tradizionali (come i modelli spazio-temporali) che i modelli ibridi al fine di valutare, a livello locale, l’impatto del settore agro-zootecnico sulla qualità dell’aria nella regione Lombardia.
Si ringraziano David Guzmán Piedrahita e Marco Vinciguerra, laureandi del corso di laurea triennale in Ingegneria Informatica presso l’Università degli Studi di Bergamo, per il loro contributo al presente articolo.